I want to start out this month's post with a simple question: What is the acceptable false-positive rate in the medical literature? Clearly, not all "positive" studies really are positive. Some achieved statistical significance by chance alone. We can never really be rid of that. So let's set a threshold. Some percentage that we'll be OK. with. One percent? Ten percent? Five?
Now, the statistically-savvy among you will be saying: "Five percent. That's what the p-value is for. A threshold for significance of P<0.05 assures that at most 5% of the positive articles we read are positive by chance." The statistically super-savvy, however, will know that that isn't true, and can stop reading now. And, of course, those with no idea what a p-value is are welcome to dive right in, with my apologies for jargon.
If you think of medical research as an expression of the scientific method (a stretch, I know), you'll see that every study has exactly four possible outcomes. I'm using drug studies as a prototypical example:
1. True Positive -- the novel drug being studied was found to be efficacious and truly works. Practice changes. The world advances.
2. True Negative -- the novel drug being studied was found not to be efficacious and it truly doesn't work. Nothing changes.
3. False Negative -- the novel drug being studied was found not to be efficacious but it truly works. The study was done wrong, or was underpowered or something. Nothing changes. The hope of future generations is lost.
4. False Positive -- the novel drug being studied was found to be efficacious but it truly doesn't work. The study was done wrong, or was only positive by chance. Practice changes. People get drugs that don't work.
For me, number 4 is the most concerning. I don't mind too much if we miss out on a potential therapy here and there, but, man, do I hate the idea of treating patients with drugs that don't work.
But how often does #4 really happen?
The answer will shock and depress you.
In an earlier Methods Man article, I pointed out the myriad ways that researchers can massage their negative data to make a positive study. I put this in (or at least close to) the fraud category, which is really hard to quantify -- but let's just assume that some of the positive studies you read are negative studies that got a bit of the old statistical back-room treatment.
Then there's publication bias. Studies are more likely to be published if they have a positive result, as they are considered more "impactful," and, after all, journals are trying to increase readership and sell ads. Related to this is the "file drawer" effect, whereby researchers don't even try to publish their negative results because they think it's not worth their time or (more concerningly) the data they found refutes their hypothesis (and thus threatens grant funding). You can actually quantify how many studies are suspiciously missing from a given field of inquiry using some cool statistics. Researchers looking at the Cochrane Database discovered that roughly half of all meta-analyses had evidence of "missing" studies.
But let's be generous. Let's ignore fraud. And publication bias. Let's assume that every hypothesis that gets tested gets tested appropriately, and all the results are published. What percent of the positive studies in the literature are actually bunk?
Here's where the p-value comes in. Now, the powers-that-be have decided that a p-value less than 0.05 is "statistically significant." That means your study is positive. And most of us are taught that the p-value is the chance that the result you got could have occurred by chance. So a p-value of 0.02 means that the results you see would be the result of chance only 2% of the time.
With that definition in mind, we can assume that somewhere around 5% of studies in the literature are false-positives (again ignoring the fraud and bias discussed above).
But that definition -- that intuitive understanding -- is dead wrong.
To see why, we have to do some math.
Let's say that there are 100,000 hypotheses out there -- floating in the ether. Some of the hypotheses are true, some are false (this is how science works, right?). It turns out that it's the proportion of true hypotheses that dictates how much of the medical literature is nonsense, not the p-value. Let me prove it.
Let's say that of our 100,000 hypotheses, 10%, or 10,000 are true. I may be a bit of a pessimist but I think I'm being pretty generous here. OK -- how many false positives will there be? Well, of the 90,000 false hypotheses, 5% (there's the p-value!) will end up appearing true in the study by chance alone. Five percent of 90,000 is 4,500 false positive studies. How many true positives will there be? Well, we have 10,000 true hypotheses -- but not all the studies will be positive. The number of positive studies will depend on how adequately "powered" they are, and power is usually set at around 80%, meaning that 8,000 of those true hypotheses will be discovered to be true when tested, while 2,000 will be missed.
So of our 100,000 hypotheses, we have a total of 12,500 positive studies. 4,500 of those 12,500 are false positives. That's 36%.
Wait -- so only 64% of the studies that have a positive result are true?
Yes.
Let that sink in. Despite the comforting nature of the 0.05 threshold for the p-value, 36% of the positive studies you read may be false.
This depends critically on the number of true hypotheses by the way. If I drop the number of true hypotheses to 5%, keeping everything else the same, then 55% of the positive studies you read are wrong. It's a disaster.
Or, choose your own true hypothesis rate, then read the percent of positive studies that are true off of this graph (I make a lot of graphs):

What's crazy about this is it has nothing to do with statistical malfeasance, nothing to do with pressure to publish or get promoted, or get a grant. It's just the numbers. Our dependence on the p-value has doomed this enterprise.
But fear not, there is a solution.
It turns out that what you can do for the body of medical literature you can do for a single study as well. All you have to do is assign a value to how likely you think the hypothesis is before the study was done. This corresponds to the "proportion of true hypotheses in the literature" factor above. Then, simply look at the results, combine them with your prior probability, and come out with an after-the-fact, or posterior probability.
How do you combine these things? A bit of simple math called Bayes Theorem, which I will not share with you here (thank me later). But I will give you a table of results. The following table assumes the study was "significant" at a level of P=0.05, and had 80% power.
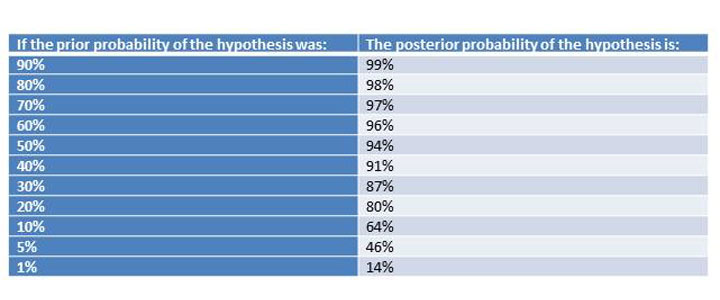 Table 1: A positive study (ignoring fraud and bias), should always raise your estimate of the likelihood of the hypothesis being true, but you only get to that magic 5% false positive rate when your prior probability is greater than 50%.
Table 1: A positive study (ignoring fraud and bias), should always raise your estimate of the likelihood of the hypothesis being true, but you only get to that magic 5% false positive rate when your prior probability is greater than 50%.
If you look at the above table, you can see something sort of magical happens around 50% prior probability. That's the point where a positive study moves you into a posterior probability that suggests an "acceptable" 5% false positive rate.
But think about that. When you are reading a study, if you're less than 50/50 on whether the thing will work or not, accepting positive findings will lead to a false-positive rate that is unacceptably high.
Now, there is some hope. For one thing, sequentially positive studies can ratchet you up that ladder pretty quickly. Let's say the hypothesis has a 10% chance of being true, but the first nice study is positive at P=0.05. Now you're up to a 64% chance of the hypothesis being true -- probably not enough to roll it out to patients unless the risk is very small, but much better. But if another study comes in that is positive at P=0.05, you're up to a 96% chance that the hypothesis is true. See? Replication works.
This approach, often labeled as Bayesian, is intuitive. It works the way our brains work, gradually adding up information bit by bit until we are convinced.
The sticking point, of course, is the prior probability. How can we rationally assign a number to this abstract concept? There are several approaches.
One is to put the onus on the person writing the paper. They present their results, and then back-calculate the prior probability such that, given their results, the posterior probability would result in a false-positive rate of no more than 5%.
For example:
"We found that drinking hot cocoa was associated with a statistically significant improvement in mood, P=0.03. To be confident that this intervention has more than a 95% chance of replication, the prior probability of the hypothesis must have been greater than 42%." They then could explain, based on all the other hot chocolate studies, why the prior probability was greater than 42%. The great thing is, you could be convinced, or not, based on your own reading of the literature.
The other thing a writer can do is report a factor that translates your prior probability into a posterior probability. This is familiar to many who read the diagnostic test literature as a likelihood ratio. It tells you, after the test (in this case the randomized trial) has been done, how much your suspicion of disease (a true hypothesis) has changed. It works regardless of what prior probability you choose; you're essentially multiplying the prior probability by the reported factor to get to the posterior probability. There's actually some logarithms involved here, but there are websites out there that do the hard work for you.
I wouldn't be much of a Methods Man if I didn't offer some solutions to the problems here. So here goes:
1. State your hypotheses. Don't make the reader work to figure out what the heck is being tested in your study. They need to know this to decide what they think the prior probability is.
2. Provide relevant background. Give your reader enough information to come up with a prior probability. And don't cherry-pick. Have some statistical ethics. Tell the whole story.
3. Add likelihood ratios or minimum Bayes factors to your manuscripts -- be the change you want to see in the world.
4. REPLICATE -- Most of these issues would be completely moot if the biological science establishment took the time (and lucre) to replicate their studies. The NIH should fund replication studies (not innovative, perhaps, but oh so crucial). I guarantee this will save money in the long term.
That's it, methodologists. If, in the future, you find yourself looking at that "statistically significant" finding and not buying it, trust your gut. Your Bayesian brain is telling you something the statistics aren't.
F. Perry Wilson, MD, is an assistant professor of medicine at the Yale School of Medicine. He earned his BA from Harvard University, graduating with honors with a degree in biochemistry. He then attended Columbia College of Physicians and Surgeons in New York City. From there he moved to Philadelphia to complete his internal medicine residency and nephrology fellowship at the Hospital of the University of Pennsylvania. During his research time, Dr. Wilson also obtained a Master of Science in Clinical Epidemiology from the University of Pennsylvania. He is an accomplished author of many scientific articles and holds several NIH grants. He is a MedPage Today reviewer, and in addition to his video analyses he authors a blog, The Methods Man. You can follow @methodsmanmd on Twitter.